RAID-5 ADAPTER LEVEL PROTECTION
RAID-5 ADAPTER LEVEL PROTECTION
At the adapter level, RAID-5 has become an industry standard method to provide increased
availability for servers. RAID-5 and RAID-1 implementations allow servers to continue
operation even if there is a 'catastrophic' failure of a hard drive.
Normal Operations
During normal operations in a RAID 5 environment, redundant information is calculated and
written out to the drives as shown above. In a 'n' disk environment, 'n-1' disks of data are
provided with 1 disk of space dedicated to redundant 'check sum' or 'parity' information. As
pictured above, three 2GB drives will provide 4GB of data space and 2GB of redundancy.
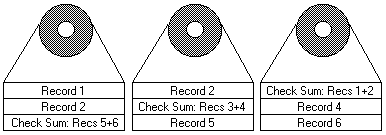
Notice that the redundant data is actually spread out over all the disks for performance reasons.
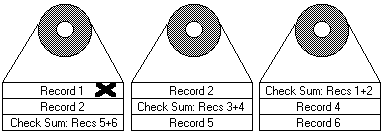
Catastrophic Disk Failure
If a drive that is a member of a RAID-5 array fails, the remaining members of the array can use
their redundant information to recalculate the lost data - either to respond to user requests for
data or to rebuild the data stored on the lost drive when it is replaced with a new one.

In the case pictured here, information in Record 1 from Drive I will be combined with the check
sum information on Drive 3 to recreate information that is not available from Drive 2. As long as
the array controller can access the remaining 'n-1' drives, the rebuild will be successful.
Naturally, if a second disk failure were to suddenly occur, the array and its data would be lost.
RAID 5 can only protect against the loss of a single drive.
Grown Sector Media Errors
Let's assume there is a read request for a file. As the drive attempts to read this data, it
determines there is a bad sector within Record 1 of Disk 1, as pictured below. If the media error
is minor, the information is corrected or remapped by the drive using the drive ECC information,
all of which is transparent to the RAID array. However, what if the disk can not recreate the
information from the ECC information on the drive? Is data still lost, as it was before without
RAID support ? In this case, IBM RAID adapters provide the additional capability to recognize
the fault and re-create the data from redundant information stored on other drives. For example,
Record 1 in the diagram will be corrected from data stored in Record 2 on Drive 2 and check sum
information on Drive 3. The RAID adapter then requests that Record 1 be rewritten, the drive
will remap the bad sector elsewhere on the drive and Record 1 will have good data.
In this case, RAID 5 has increased the availability of the information by re-creating data that
otherwise would have been lost. However, the initial assumption is that this process has been
initiated by accessing this data on the drive. If this data is not accessed, this error will not be
detected. This can become a real problem if a catastrophic failure occurs before the data is
corrected.
Combination Failures
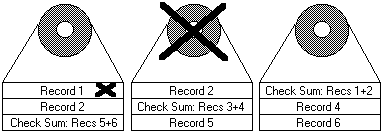
Consider the example shown above. Here, we have an undetected sector media error within
Record 1 of Disk 1. This error is undetected because it happens to have occurred within an
archived section of the users database that is seldom accessed. Before this error is recognized
and corrected, we sustain a 'catastrophic' failure of Drive 2. So far, no data problems are
noticed. User requests for information other than Record 1 can still be serviced with RAID
protection and data recalculation. However, when drive 2 is replaced and a rebuild is initiated,
the RAID controller will attempt to recalculate Record 2 from the failed Drive 2 by combining
Record 1 with the check sum data on Drive 3. At this point, the media sector error is discovered.
If the ermr is minor, the disk can re-create the missing information from its FCC data (as before)
and potentially remap the bad sector. However, if the error is too severe, the disk will not be able
to recover the data. The rebuild process can not complete successfully because it does not have a
complete Record I to combine with the check sum data to rebuild the lost data on drive 2. In this
case, the Rebuild will skip that stripe and continue rebuilding the rest of the logical drive. Once
the rebuild has completed, a 'rebuild failed' message is displayed. The IBM ServeRAlD and the
IBM ServeRAlD II adapters will bring the rebuilt drive online and take the array out of 'critical'
mode. In order to protect data integrity, it will also block access to the damaged stripes of the
array. Data files covered by these damaged stripes will still report data errors and need to be
restored from a previous backup. This prevents the necessity of a full restore due to a 'rebuild
failed' message that is caused by one or two bad stripes. In the case of non-ServeRAlD
Adapters, the customer will need to use the RAID configuration previously saved to a diskette, in
order to bring the array back online.
Back to 
Please see the LEGAL - Trademark notice.
Feel free - send a  for any BUG on this page found - Thank you.
for any BUG on this page found - Thank you.